重庆搜索引擎制作全攻略
这个教程将引导你构建一个专注于重庆的垂直搜索引擎,我们将把它分为三个阶段:
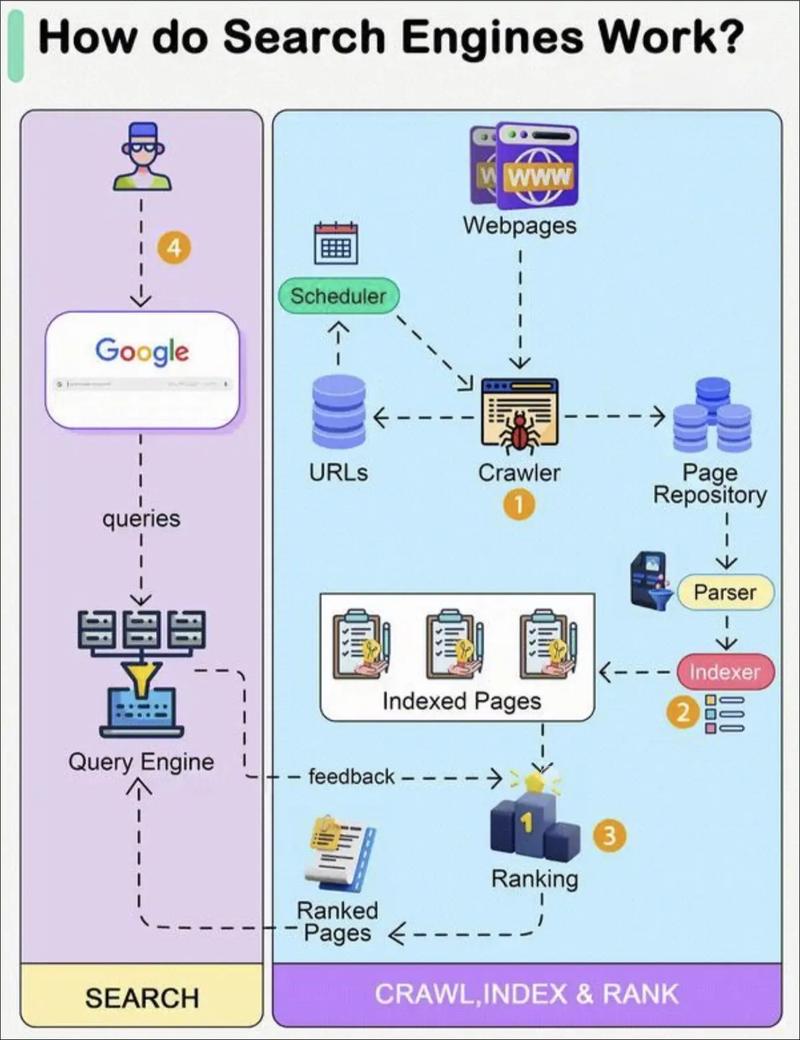
- 第一阶段:规划与准备
- 第二阶段:核心技术开发
- 第三阶段:产品优化与上线
第一阶段:规划与准备
在敲下第一行代码之前,清晰的规划至关重要。
明确搜索引擎的定位与目标
你的“重庆搜索引擎”具体是什么?这决定了你的技术方向。
-
定位A:重庆生活服务搜索引擎
- 目标: 帮助用户快速找到重庆的美食、景点、住宿、交通、购物等信息。
- 数据来源: 大众点评、美团、高德地图、携程、百度地图等公开API或通过爬虫抓取。
- 特点: 强调“实用性”和“本地化”,结果可能是商家列表、地址、电话、评分等结构化信息。
-
定位B:重庆旅游文化搜索引擎
 (图片来源网络,侵删)
(图片来源网络,侵删)- 目标: 提供关于重庆历史、文化、方言、景点、名人、事件的深度信息。
- 数据来源: 重庆市政府官网、重庆日报、维基百科、旅游博客、知乎等。
- 特点: 强调“内容深度”和“知识性”,结果可能是文章、百科词条、图片、视频等。
-
定位C:通用重庆信息聚合引擎
- 目标: 结合A和B,提供更全面的重庆信息。
- 数据来源: 综合以上所有来源。
- 特点: 范围广,但需要更强的数据整合和排序能力。
建议: 初学者可以从 定位A (生活服务) 或 定位B (旅游文化) 入手,专注于一个领域,更容易做出成果。
确定核心功能
- 基础功能:
- 关键词搜索
- 搜索结果分页
- 搜索结果排序(按相关度、按热度、按距离等)
- 进阶功能(可选):
- 筛选/分类: 按区域(渝中区、沙坪坝区等)、按类别(火锅、串串、江景房等)筛选。
- 自动补全/联想: 用户输入“解放碑”时,自动提示“解放碑步行街”、“解放碑好吃街”。
- 搜索纠错: 用户输入“洪崖洞”时,如果输入错误(如“洪崖同”),能自动纠正。
- 语音搜索: 方言或普通话语音输入。
- 地图集成: 搜索结果直接在地图上展示。
技术选型
这是制作搜索引擎的核心,我们采用目前最主流、最高效的技术栈。
-
数据抓取层:
 (图片来源网络,侵删)
(图片来源网络,侵删)- Python + Scrapy: 强大的爬虫框架,适合大规模、结构化的数据抓取。
- Selenium/Playwright: 用于抓取JavaScript渲染的动态网页(很多现代网站都用)。
- 代理IP池: 避免被目标网站封禁。
- 定时任务: 使用
Celery+Redis或Airflow定期更新数据。
-
数据处理与存储层:
- 数据库:
- MySQL / PostgreSQL: 存储结构化数据,如商家信息、用户评分等。
- MongoDB: 存储非结构化或半结构化数据,如抓取的HTML页面全文、文章内容等。
- 搜索引擎核心:
- Elasticsearch: 这是我们的不二之选! 它是一个基于Lucene库的开源、分布式、RESTful风格的搜索和数据分析引擎,专门为全文检索、高可用性和可扩展性而设计,是现代搜索引擎的基石。
- 消息队列: RabbitMQ / Kafka。 用于解耦数据抓取和数据处理流程,提高系统稳定性和可扩展性。
- 数据库:
-
应用服务层:
- 后端框架:
- Python:
- Django: 全能型框架,自带ORM、后台管理,开发效率高。
- Flask: 轻量级框架,灵活自由,适合构建API服务。
- Go / Java: 性能更高,适合高并发场景,但对开发要求也更高。
- Python:
- 前端框架:
- Vue.js / React: 现代前端框架,用于构建交互性强的用户界面。
- 基础HTML/CSS/JavaScript: 如果只是做一个简单的展示页面,用这个就足够了。
- 后端框架:
数据获取与合规性
- 数据来源: 优先选择提供官方API的平台(如高德地图、大众点评开放平台),这最稳定、最合规。
- 爬虫注意事项:
- 遵守
robots.txt协议: 在抓取任何网站前,先检查其robots.txt文件,了解哪些页面可以抓取。 - 控制频率: 设置合理的抓取间隔,避免对目标服务器造成过大压力。
- 声明身份: 在HTTP请求头中加入你的联系方式,表明你是谁。
- 版权问题: 明确数据的使用范围,尊重原创,不要用于商业用途。
- 遵守
第二阶段:核心技术开发
我们将以 定位A:重庆生活服务搜索引擎 为例,使用 Python + Flask + Elasticsearch 技术栈进行开发。
步骤1:环境搭建
- 安装Python和相关库:
pip install flask elasticsearch requests scrapy
- 安装Elasticsearch:
- 前往 Elasticsearch官网 下载对应操作系统的版本。
- 解压并运行
bin/elasticsearch(Linux/Mac) 或bin\elasticsearch.bat(Windows)。 - 访问
http://localhost:9200,看到类似{"name": "...", "cluster_name": "...", "version": {...}, "tagline": "..."}的JSON响应,说明安装成功。
步骤2:数据抓取 (使用Scrapy)
-
创建Scrapy项目:
scrapy startproject chongqing_spider cd chongqing_spider scrapy genspider chongqing_food meituan.com # 示例:抓取美团上的重庆美食
-
编写爬虫 (
chongqing_food.py):- 使用XPath或CSS选择器从页面提取数据,如店名、地址、评分、电话等。
- 将提取的数据存为字典格式。
# chongqing_spider/spiders/chongqing_food.py import scrapy class ChongqingFoodSpider(scrapy.Spider): name = 'chongqing_food' allowed_domains = ['meituan.com'] # 注意:这里只是一个示例URL,实际抓取需要分析页面结构 start_urls = ['https://meituan.com/chongqing/food'] def parse(self, response): # 假设每个商家信息在一个class为 'shop-item' 的div里 shops = response.css('div.shop-item') for shop in shops: yield { 'name': shop.css('a.shop-name::text').get(), 'address': shop.css('span.address::text').get(), 'rating': shop.css('span.rating::text').get(), 'phone': shop.css('span.phone::text').get(), 'category': '火锅' # 可以根据URL或其他信息判断 } -
运行爬虫并保存数据:
scrapy crawl chongqing_food -o chongqing_food.json
这会生成一个
chongqing_food.json文件,里面是抓取到的JSON数据。
步骤3:数据导入Elasticsearch
Elasticsearch中的数据被组织成 索引,每个索引包含多个 文档。
-
创建Python脚本导入数据 (
import_to_es.py):from elasticsearch import Elasticsearch import json # 连接到Elasticsearch es = Elasticsearch(["http://localhost:9200"]) # 定义索引名称和映射(Mapping,类似于数据库表结构) index_name = "chongqing_shops" mapping = { "mappings": { "properties": { "name": {"type": "text", "analyzer": "ik_max_word"}, # 文本类型,支持分词 "address": {"type": "text", "analyzer": "ik_max_word"}, "rating": {"type": "float"}, "phone": {"type": "keyword"}, # 关键词类型,不分词,用于精确匹配 "category": {"type": "keyword"}, "location": {"type": "geo_point"} # 地理坐标点,用于地图搜索 } } } # 如果索引不存在,则创建 if not es.indices.exists(index=index_name): es.indices.create(index=index_name, body=mapping) print(f"索引 '{index_name}' 创建成功") # 读取JSON文件并导入 with open('chongqing_food.json', 'r', encoding='utf-8') as f: for line in f: shop = json.loads(line) # 这里可以添加经纬度信息,用于地理搜索 # shop['location'] = {"lat": 29.56, "lon": 106.55} es.index(index=index_name, body=shop) print(f"已导入: {shop['name']}") print("数据导入完成!")注意:
ik_max_word是中文分词器,你需要安装 IK Analysis for Elasticsearch 插件来支持中文分词。
步骤4:搭建搜索API (使用Flask)
现在创建一个简单的Web服务,让用户可以通过HTTP请求来搜索。
-
创建Flask应用 (
app.py):from flask import Flask, request, jsonify from elasticsearch import Elasticsearch app = Flask(__name__) es = Elasticsearch(["http://localhost:9200"]) @app.route('/search') def search(): # 从URL参数中获取查询关键词 q = request.args.get('q', '') # 从URL参数中获取页码 page = int(request.args.get('page', 1)) # 每页显示多少条结果 size = 10 if not q: return jsonify({"error": "请提供查询关键词"}), 400 # 构建Elasticsearch查询语句 # 使用bool查询,must表示必须匹配,filter表示过滤(不计算相关度) query = { "query": { "bool": { "must": [ { "multi_match": { "query": q, "fields": ["name^3", "address^2", "category"], # name字段权重更高 "type": "best_fields" } } ], "filter": [ {"term": {"category": "火锅"}} # 可选:增加过滤条件 ] } }, "from": (page - 1) * size, # 分页起始位置 "size": size } # 执行搜索 response = es.search(index="chongqing_shops", body=query) # 提取结果并格式化 results = [] for hit in response['hits']['hits']: results.append(hit['_source']) # 返回JSON格式的搜索结果 return jsonify({ "results": results, "total": response['hits']['total']['value'], "page": page }) if __name__ == '__main__': app.run(debug=True) -
运行Flask应用:
python app.py
现在你的搜索API已经运行在
http://127.0.0.1:5000上了。
步骤5:创建前端界面
创建一个简单的 index.html 文件。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">重庆搜索引擎</title>
<style>
body { font-family: sans-serif; text-align: center; margin-top: 50px; }
#search-box { width: 300px; padding: 10px; }
button { padding: 10px 20px; }
#results { margin-top: 20px; text-align: left; width: 600px; margin: 20px auto; }
.result-item { border: 1px solid #ccc; padding: 10px; margin-bottom: 10px; border-radius: 5px; }
</style>
</head>
<body>
<h1>重庆搜索引擎</h1>
<div>
<input type="text" id="search-box" placeholder="搜索重庆美食...">
<button onclick="doSearch()">搜索</button>
</div>
<div id="results"></div>
<script>
function doSearch() {
const q = document.getElementById('search-box').value;
const resultsDiv = document.getElementById('results');
if (!q) {
resultsDiv.innerHTML = '<p>请输入搜索关键词</p>';
return;
}
// 调用后端API
fetch(`/search?q=${encodeURIComponent(q)}`)
.then(response => response.json())
.then(data => {
let html = `<p>找到 ${data.total} 条结果</p>`;
data.results.forEach(result => {
html += `
<div class="result-item">
<h3>${result.name}</h3>
<p>地址: ${result.address}</p>
<p>评分: ${result.rating}</p>
<p>电话: ${result.phone}</p>
</div>
`;
});
resultsDiv.innerHTML = html;
})
.catch(error => {
resultsDiv.innerHTML = '<p>搜索出错,请稍后重试。</p>';
console.error('Error:', error);
});
}
</script>
</body>
</html>
打开 index.html 文件,在输入框中输入“火锅”,点击搜索,你就能看到从Elasticsearch中返回的结果了!
第三阶段:产品优化与上线
一个能用的搜索引擎和好用的搜索引擎之间还有差距。
用户体验优化
- 搜索框优化: 实现搜索框自动聚焦、搜索历史记录。
- 结果页优化:
- 高亮显示: 在搜索结果中高亮显示匹配的关键词。
- 排序功能: 提供按“相关度”、“评分”、“距离”排序的选项。
- 分页优化: 使用“加载更多”代替传统分页。
- 结果摘要: 显示匹配内容的部分片段。
- 响应式设计: 确保网站在手机和电脑上都能良好显示。
性能优化
- 缓存: 对热门查询结果进行缓存(如使用Redis),减轻Elasticsearch的压力。
- 异步处理: 使用Celery等工具处理耗时的任务,如数据更新。
- Elasticsearch调优:
- 根据查询模式调整索引分片和副本数量。
- 使用更合适的分词器和分析器。
- 对不常变的字段使用
doc_values优化。
部署上线
- 选择云服务器: 阿里云、腾讯云、华为云等,选择配置合适的ECS(弹性计算服务)。
- 使用Docker: 将你的Flask应用、Elasticsearch以及相关服务打包成Docker容器,实现环境一致性和轻松部署。
- 使用Nginx: 作为反向代理服务器,处理静态文件请求、负载均衡,并配置SSL证书实现HTTPS。
- 持续集成/持续部署: 使用GitHub Actions或Jenkins,当代码更新时自动部署到服务器。
制作一个“重庆搜索引擎”是一个综合性的项目,它涵盖了网络爬虫、数据处理、搜索引擎核心、后端API和前端开发等多个方面。
给初学者的建议:
- 从小处着手: 先实现最核心的“搜索”功能,再逐步添加筛选、排序等附加功能。
- 善用开源工具: Elasticsearch已经为你解决了99%的搜索难题,不要重复造轮子。
- 重视数据质量: “垃圾进,垃圾出”,确保你抓取和导入的数据是准确和干净的。
- 学习官方文档: Elasticsearch和Flask的官方文档是最好的老师。
这个教程为你提供了一个清晰的路线图,祝你项目顺利,成功打造出属于你自己的“重庆搜索引擎”!


