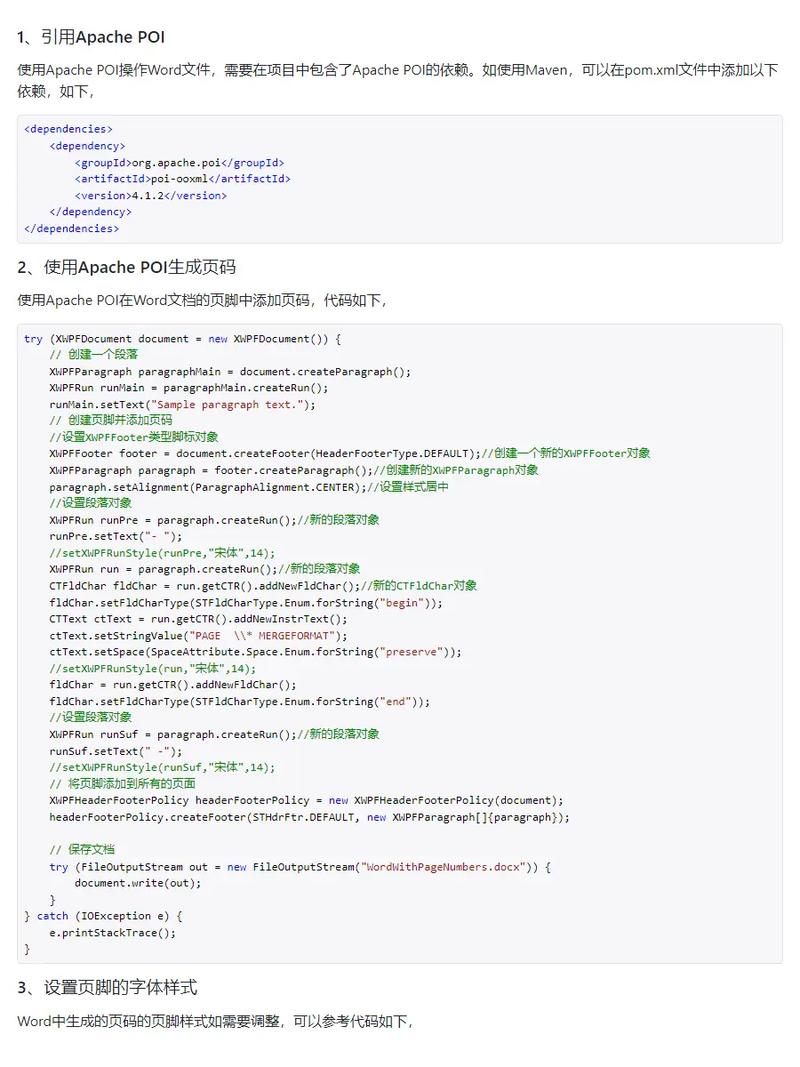
Java读取网页源码终极指南:从入门到精通,附5种高效方法与实战代码
** 还在为用Java获取网页内容而烦恼?本文手把手教你从最基础的URL连接到高效的Jsoup解析,再到处理动态加载的AJAX页面,一篇搞定所有场景,让你轻松实现网络爬虫、数据抓取等功能!

引言:为什么你需要用Java读取网页源码?
在当今数据驱动的时代,从互联网上自动获取信息(即网络爬虫或数据抓取)已成为一项至关重要的技能,无论是进行市场竞品分析、舆情监控、学术研究,还是构建个性化推荐系统,第一步往往就是读取目标网页的源码。
Java,作为一门稳定、强大且跨平台的编程语言,是实现这一任务的绝佳选择,它拥有成熟的网络库和强大的生态,能够稳定、高效地处理各种复杂的网络请求。
本文将作为你的终极指南,系统性地介绍如何使用Java读取网页的所有源码,无论你是刚入门的Java新手,还是寻求更优解决方案的资深开发者,都能在这里找到适合你的方法。
准备工作:Java网络编程的基石
在开始编写代码之前,我们需要了解Java中处理网络请求的核心类,它们都位于 java.net 包中。
URL类: 代表一个统一资源定位符,也就是我们常说的网址,它是我们访问网络资源的入口。HttpURLConnection类: 一个抽象类,它提供了向HTTP URL发起请求并获取响应的标准方法,它功能强大,支持GET、POST等多种请求方式,可以设置请求头、处理Cookies等。BufferedReader和InputStreamReader: 用于高效地读取从网络连接中获取的输入流,避免内存浪费。
重要提示: 在实际项目中,我们通常不会直接使用这些原生API,因为它们代码冗长且容易出错,但了解它们有助于我们理解底层原理。
方法一:原生HttpURLConnection实现(基础入门)
这是最传统、最基础的方法,不依赖任何第三方库,适合理解Java网络通信的底层逻辑。
核心思路:
- 创建一个
URL对象。 - 通过
URL对象的openConnection()方法获取HttpURLConnection实例。 - 设置请求方法(如
GET)和请求头。 - 发起请求并获取输入流。
- 使用
BufferedReader逐行读取输入流,并拼接成最终的源码字符串。
实战代码:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class BasicWebReader {
public static String fetchWebPageSource(String urlString) throws IOException {
// 1. 创建URL对象
URL url = new URL(urlString);
// 2. 打开连接
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
// 3. 设置请求方法
connection.setRequestMethod("GET");
// 4. 设置请求头(模拟浏览器访问,避免被拦截)
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36");
// 5. 获取响应码,200表示成功
int responseCode = connection.getResponseCode();
System.out.println("Response Code: " + responseCode);
if (responseCode == HttpURLConnection.HTTP_OK) {
// 6. 获取输入流
BufferedReader in = new BufferedReader(new InputStreamReader(connection.getInputStream()));
String inputLine;
StringBuilder content = new StringBuilder();
// 7. 逐行读取
while ((inputLine = in.readLine()) != null) {
content.append(inputLine);
content.append(System.lineSeparator()); // 保留换行
}
// 8. 关闭流
in.close();
return content.toString();
} else {
throw new IOException("GET request failed with response code: " + responseCode);
}
}
public static void main(String[] args) {
String targetUrl = "http://example.com"; // 替换成你想抓取的网址
try {
String sourceCode = fetchWebPageSource(targetUrl);
System.out.println("--- 网页源码 (前500字符) ---");
System.out.println(sourceCode.length() > 500 ? sourceCode.substring(0, 500) + "..." : sourceCode);
} catch (IOException e) {
e.printStackTrace();
}
}
}
优缺点分析:
- 优点: 无需额外依赖,是理解Java网络编程的绝佳教材。
- 缺点: 代码繁琐,处理HTML解析、JavaScript渲染等复杂场景时力不从心。
方法二:Jsoup——解析HTML的神器(强烈推荐)
对于网页源码的读取和解析,Jsoup 是目前Java生态中最流行、最强大的库,它不仅简化了HTTP请求,更提供了类似jQuery的CSS选择器,让你能轻松地从HTML中提取所需数据。
核心思路:
- 在你的项目中添加Jsoup依赖(Maven/Gradle)。
- 使用
Jsoup.connect(url).get()方法,它会自动发起GET请求并返回一个Document对象。 Document对象代表了整个HTML文档,你可以通过select()方法,使用CSS选择器精准地定位元素。
第一步:添加依赖 (Maven)
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.17.2</version> <!-- 请使用最新版本 -->
</dependency>
实战代码:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class JsoupWebReader {
public static void main(String[] args) {
String targetUrl = "http://example.com";
try {
// 1. Jsoup自动发起GET请求并解析HTML
Document doc = Jsoup.connect(targetUrl)
.userAgent("Mozilla/5.0") // 设置User-Agent
.timeout(10000) // 设置超时时间
.get();
// 2. 获取完整的HTML源码
System.out.println("--- 完整HTML源码 ---");
String fullHtmlSource = doc.html();
System.out.println(fullHtmlSource.length() > 500 ? fullHtmlSource.substring(0, 500) + "..." : fullHtmlSource);
// 3. 解析并提取数据(示例:获取页面所有链接)
System.out.println("\n--- 页面所有链接 ---");
Elements links = doc.select("a[href]"); // 使用CSS选择器
for (Element link : links) {
System.out.println("链接文本: " + link.text() + " | 链接地址: " + link.attr("abs:href"));
}
// 4. 提取标题
System.out.println("\n--- 页面标题 ---");
String title = doc.title();
System.out.println(title);
} catch (IOException e) {
e.printStackTrace();
}
}
}
优缺点分析:
- 优点: 代码极其简洁,功能强大(解析、遍历、修改HTML),支持CSS和jQuery选择器,是处理静态网页的首选方案。
- 缺点: 无法执行JavaScript,因此无法获取由JS动态加载的内容。
方法三:处理AJAX与动态加载页面(进阶挑战)
现代网站(如淘宝、知乎、微博)大量使用JavaScript(AJAX/Fetch API)在页面加载后动态获取数据,即使你用Jsoup获取了源码,也无法看到这些动态加载的内容。
解决方案:使用无头浏览器
无头浏览器是一个没有图形界面的浏览器,它可以像真实用户一样执行JavaScript,渲染出完整的网页,我们可以通过Java来驱动它。
推荐工具:Selenium + WebDriver
核心思路:
- 下载对应浏览器的WebDriver(如ChromeDriver)。
- 在Java项目中添加Selenium依赖。
- 启动WebDriver,让它加载目标网页。
- 设置一个等待时间,确保JS有足够时间执行。
- 从浏览器中获取最终的、经过JS渲染后的HTML源码。
第一步:添加依赖 (Maven)
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.18.1</version> <!-- 请使用最新版本 -->
</dependency>
实战代码:
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.util.concurrent.TimeUnit;
public class DynamicWebReader {
public static void main(String[] args) {
// 1. 指定ChromeDriver的路径(需要提前下载并配置好)
// System.setProperty("webdriver.chrome.driver", "path/to/your/chromedriver.exe");
// 2. 配置无头模式(后台运行)
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--disable-gpu");
options.addArguments("--window-size=1920,1080");
WebDriver driver = null;
try {
driver = new ChromeDriver(options);
// 3. 打开目标网页(这里以一个动态加载的示例网站为例)
// 注意:这类网站结构易变,代码可能需要调整
String targetUrl = "https://example.com/dynamic-content"; // 替换为真实目标
driver.get(targetUrl);
// 4. 隐式等待,等待最多10秒,让JS加载完成
driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
// 5. (可选)点击某个按钮触发加载
// WebElement loadMoreButton = driver.findElement(By.id("load-more-button"));
// loadMoreButton.click();
// driver.manage().timeouts().implicitlyWait(10, TimeUnit.SECONDS);
// 6. 获取渲染后的完整HTML源码
String renderedSource = driver.getPageSource();
System.out.println("--- 渲染后的HTML源码 (前500字符) ---");
System.out.println(renderedSource.length() > 500 ? renderedSource.substring(0, 500) + "..." : renderedSource);
} catch (Exception e) {
e.printStackTrace();
} finally {
// 7. 关闭浏览器,释放资源
if (driver != null) {
driver.quit();
}
}
}
}
优缺点分析:
- 优点: 终极解决方案,能处理任何复杂的动态网页,效果与手动打开浏览器完全一致。
- 缺点: 配置相对复杂,性能开销大(启动浏览器),速度慢。
方法四:Apache HttpClient(企业级HTTP客户端)
对于需要处理复杂HTTP请求(如自定义Header、处理Cookies、执行POST请求)的企业级应用,Apache HttpClient 是比 HttpURLConnection 更专业、更强大的选择。
核心思路: 与原生方法类似,但API设计更人性化,功能更完善。
第一步:添加依赖 (Maven)
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.14</version> <!-- 请使用最新版本 -->
</dependency>
实战代码(简版):
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
public class ApacheHttpClientReader {
public static void main(String[] args) {
String targetUrl = "http://example.com";
// 使用try-with-resources确保资源关闭
try (CloseableHttpClient httpClient = HttpClients.createDefault()) {
HttpGet request = new HttpGet(targetUrl);
request.setHeader("User-Agent", "Mozilla/5.0");
try (CloseableHttpResponse response = httpClient.execute(request)) {
HttpEntity entity = response.getEntity();
if (entity != null) {
// 使用EntityUtils直接将实体内容转为字符串,非常方便
String sourceCode = EntityUtils.toString(entity);
System.out.println("--- 网页源码 (前500字符) ---");
System.out.println(sourceCode.length() > 500 ? sourceCode.substring(0, 500) + "..." : sourceCode);
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
优缺点分析:
- 优点: 功能全面,稳定可靠,是企业级应用的标准选择。
- 缺点: 需要引入额外的第三方库。
方法五:Java 11+ 的HttpClient(现代Java的选择)
如果你使用的是Java 11或更高版本,恭喜你!Java标准库中已经内置了一个全新的、现代化的 java.net.http.HttpClient,它结合了 HttpURLConnection 和 HttpClient 的优点,并支持异步请求。
核心思路:
使用 HttpClient.newHttpClient() 创建客户端,构建请求,然后同步或异步发送。
实战代码:
import java.io.IOException;
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
public class ModernJavaHttpClientReader {
public static void main(String[] args) throws IOException, InterruptedException {
String targetUrl = "http://example.com";
// 1. 创建HttpClient
HttpClient client = HttpClient.newBuilder()
.version(HttpClient.Version.HTTP_2)
.connectTimeout(Duration.ofSeconds(10))
.build();
// 2. 创建HttpRequest
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(targetUrl))
.header("User-Agent", "ModernJavaHttpClient")
.GET()
.build();
// 3. 发送请求并获取响应(同步方式)
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
// 4. 打印结果
System.out.println("Status Code: " + response.statusCode());
System.out.println("--- 网页源码 (前500字符) ---");
String body = response.body();
System.out.println(body.length() > 500 ? body.substring(0, 500) + "..." : body);
}
}
优缺点分析:
- 优点: 标准库,无依赖,API现代化,支持HTTP/2和异步编程,是Java未来的趋势。
- 缺点: 需要Java 11+环境,对于一些高级功能(如Cookie管理)可能不如Apache HttpClient灵活。
总结与最佳实践:如何选择?
| 方法 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 原生HttpURLConnection | 学习Java网络基础、无依赖环境 | 无需库,理解原理 | 代码繁琐,功能有限 |
| Jsoup | 绝大多数静态网页、HTML解析 | 简单、强大、功能聚焦,CSS选择器神器 | 无法执行JS |
| Selenium + WebDriver | AJAX/JS动态加载页面 | 效果最真实,无死角 | 性能差,配置复杂,速度慢 |
| Apache HttpClient | 企业级应用、复杂HTTP请求 | 功能全面,稳定,社区支持好 | 需要引入第三方库 |
| Java 11+ HttpClient | 现代Java项目、追求简洁 | 标准库,无依赖,支持HTTP/2/异步 | 需要高版本Java |
最佳实践建议:
- 首选Jsoup: 对于80%的网页抓取需求,特别是内容展示类网站,直接使用 Jsoup,它能以最少的代码完成任务,是你的“瑞士军刀”。
- 用Selenium: 当发现用Jsoup获取的内容不全时,果断切换到 Selenium,虽然慢,但能解决问题。
- 企业级项目用Apache HttpClient: 如果你的应用需要处理复杂的认证、会话和请求头,且不希望引入过多第三方库(除了它本身),Apache HttpClient 是最稳妥的选择。
- 拥抱新标准: 如果你的项目已经升级到 Java 11+,优先考虑使用内置的 HttpClient,它代表了未来的方向。
注意事项与道德规范
- 遵守
robots.txt: 在抓取任何网站前,请务必检查其根目录下的robots.txt文件,了解网站所有者对爬虫的规则和限制。 - 设置合理的请求频率: 不要在短时间内向同一服务器发送大量请求,这会给对方服务器造成巨大压力,甚至可能导致你的IP被封锁,请在代码中加入
Thread.sleep()来模拟人类访问的间隔。 - 尊重版权和隐私: 抓取的数据仅用于个人学习或合法合规的业务目的,切勿用于商业用途或侵犯他人隐私。
- 处理异常和反爬机制: 网站可能会通过验证码、IP封禁等手段反爬,你的代码需要具备一定的健壮性,能够处理各种网络异常和反爬策略。
通过本文,你已经系统地掌握了使用Java读取网页源码的多种方法,从基础到进阶,从静态到动态,你可以根据具体需求,选择最适合的工具,开启你的数据采集之旅了。
技术是服务于目标的,理解每种工具的优缺点,并能在实践中灵活运用,才是成为一名优秀开发者的关键,祝你编码愉快!
你觉得哪种方法最适合你?欢迎在评论区留言讨论!


