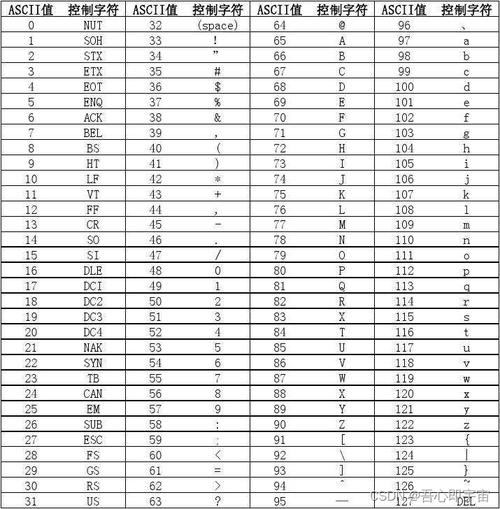
什么是网页编码?
网页编码(字符编码)就是一套“密码本”,它规定了计算机如何将我们看到的字符(中, a, )转换成二进制数据(0和1),以及如何将二进制数据转换回字符。

(图片来源网络,侵删)
- 字符:你能在屏幕上看到的所有文字、符号、表情等。
- 编码:将字符映射成二进制数字的规则。
- 解码:将二进制数字反向还原成字符的规则。
如果浏览器(解码方)使用的“密码本”和网页服务器(编码方)使用的“密码本”不一致,就会出现乱码。
GBK 编码
是什么?
GBK 是一个中文字符编码标准的全称是《汉字内码扩展规范》,它是在中国的国家标准 GB2312 的基础上扩展而来的。
- 主要特点:
- 双字节编码:一个中文字符通常占用 2 个字节。
- 兼容性:完全兼容
GB2312,可以表示GB2312里的所有汉字和符号。 - 范围:主要收录了汉字和符号,对于非中日韩的字符(如欧洲字母、阿拉伯文、emoji等)支持非常有限或不支持。
优点
- 在处理纯中文或中日韩混合内容时,存储空间相对
UTF-8会更小一点(因为一个汉字是2字节,而UTF-8中汉字通常是3字节)。 - 在一些老旧的 Windows 系统或特定行业软件中,可能是默认或唯一支持的编码。
缺点
- 国际通用性差:无法表示世界上绝大多数语言的字符,如果你的网站内容包含英文、俄文、法文、阿拉伯文等,使用
GBK就无法正确显示。 - 技术生态边缘化:现代 Web 开发、操作系统、数据库等主流技术栈都优先推荐甚至默认使用
UTF-8。GBK已经被视为一种过时的、需要被淘汰的编码。
UTF-8 编码
是什么?
UTF-8 是 Unicode(万国码) 标准的一种最常用的实现方式。
- Unicode:这是一个字符集,它为世界上几乎所有的字符都分配了一个唯一的数字(称为“码点”,Code Point),
中的码点是U+4E2D,它本身只是一个“字符列表”,不规定如何存储。 - UTF-8:它是一种变长编码方案,它将 Unicode 码点转换成 1 到 4 个不等的字节进行存储。
- 英文、数字、符号:通常用 1 个字节 表示(与
ASCII兼容)。 - 常用汉字、日文、韩文:通常用 3 个字节 表示。
- 生僻汉字、emoji、古文字等:可能用 4 个字节 表示。
- 英文、数字、符号:通常用 1 个字节 表示(与
优点
- 通用性强:可以表示全球几乎所有语言的字符,是真正的“万国码”。
- 兼容性好:完全向后兼容
ASCII,所以处理纯英文文本时非常高效。 - 生态标准:是现代 Web 开发的事实标准,从 HTML5 开始,
<meta charset="UTF-8">已经成为推荐的标准写法,所有现代浏览器、服务器、操作系统都对其有完美的支持。
缺点
- 存储空间:对于纯中文内容,一个汉字占 3 字节,比
GBK的 2 字节要大 50%,但在现代互联网,硬盘和网络带宽成本已大幅降低,这点劣势几乎可以忽略不计。
对比总结表
| 特性 | GBK 编码 | UTF-8 编码 |
|---|---|---|
| 字符集范围 | 主要支持中文、日文、韩文等 CJK 字符,以及部分符号 | 支持全球所有语言的字符,包括 emoji |
| 编码方式 | 主要是双字节(汉字) | 变长编码(1-4字节) |
| 通用性 | 差,区域性标准,国际化支持不足 | 极佳,全球通用标准 |
| 技术生态 | 过时,老旧系统或特定领域使用 | 现代标准,Web、操作系统、数据库首选 |
| 存储效率 | 对中文更高效(2字节/汉字) | 对英文更高效(1字节/字符),中文略大(3字节/汉字) |
| 推荐度 | 不推荐,仅用于维护老旧项目 | 强烈推荐,所有新项目的首选 |
如何在网页中指定编码?
在 HTML 文件中,通常通过 <meta> 标签来指定编码,这个标签必须放在 <head> 标签的开头位置,越早越好,以便浏览器在解析页面内容之前就能知道如何解码。
(图片来源网络,侵删)
标准写法(推荐):
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">我的网页</title>
</head>
<body>
<h1>你好,世界!Hello, World! 👋</h1>
</body>
</html>
charset="UTF-8":明确告诉浏览器,这个页面使用的是 UTF-8 编码。
过时的写法(不推荐,但可能还会在一些老代码中见到):
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
乱码问题排查
如果你的网页出现乱码,通常是因为以下原因之一:
-
HTML 文件本身保存的编码与声明的编码不一致:
- 问题:你用记事本或编辑器保存文件时,选择了
GBK编码,但在 HTML 中却写了<meta charset="UTF-8">。 - 解决:确保编辑器保存文件时使用的编码是
UTF-8(很多编辑器会自动检测或让你选择)。
- 问题:你用记事本或编辑器保存文件时,选择了
-
Web 服务器返回的 HTTP 头信息与 HTML 声明的编码不一致:
- 问题:服务器配置错误,在 HTTP 响应头中指定了
Content-Type: text/html; charset=GBK,但 HTML 文件里写的是UTF-8。 - 解决:需要配置你的 Web 服务器(如 Nginx, Apache)来返回正确的
Content-Type头。
- 问题:服务器配置错误,在 HTTP 响应头中指定了
结论与建议
对于任何新的网页项目,都请毫不犹豫地选择 UTF-8。
- 它是未来:
GBK正在逐渐退出历史舞台。 - 它是标准:能让你免于处理各种复杂的国际化乱码问题。
- 它是最佳实践:所有现代开发工具和框架都默认支持
UTF-8。
只有在维护一个非常老旧的、且确定只在中国大陆使用的系统时,你才可能需要与 GBK 打交道。


