MySQL 表分区完全教程
目录
- 什么是表分区?
- 为什么要使用分区?(优势)
- 分区的类型
- 分区的限制与注意事项
- 实战演练:创建和管理分区表
- 分区管理常用操作
- 总结与最佳实践
什么是表分区?
表分区 是一种“分而治之”的思想,它将一个大表(物理上)根据某种规则拆分成多个更小、更易于管理的片段,这些片段被称为 分区。
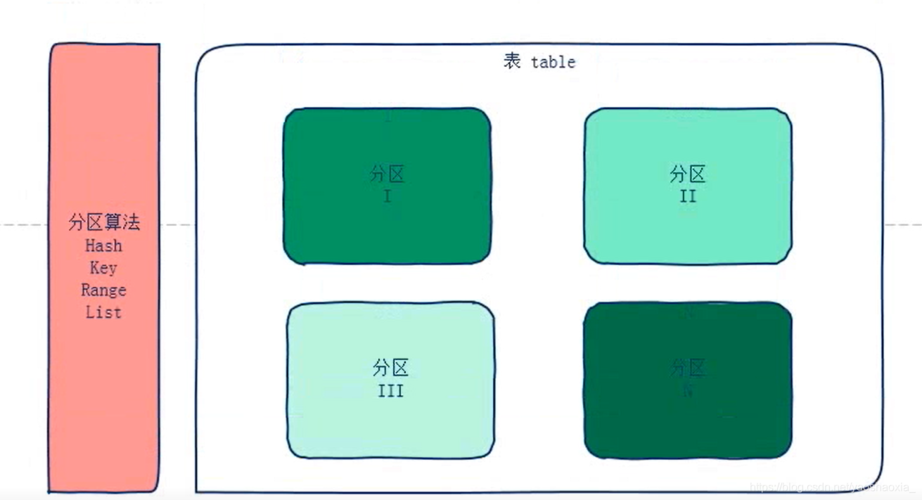
从逻辑上看,这个表仍然是一个完整的表,对应用程序和 SQL 查询是透明的,但在物理上,数据被存储在不同的文件或文件组中。
一个简单的比喻:
- 无分区表:就像一个大仓库,所有物品都堆在一起,找东西(查询)和管理(维护)都很慢。
- 分区表:就像一个大仓库被分成了 A, B, C... 多个独立的小房间,你可以只去 A 房间找东西(查询),或者只清理 B 房间(维护),效率大大提高。
为什么要使用分区?(优势)
分区的主要目的是 提高数据库的性能、可管理性和可用性。
- 提升查询性能:
- 当查询条件中包含分区键时,MySQL 可以 “分区裁剪”,只扫描相关的分区,而不是全表扫描,查询
WHERE create_date > '2025-01-01',如果表按create_date分区,MySQL 只会扫描 2025 年之后的分区。
- 当查询条件中包含分区键时,MySQL 可以 “分区裁剪”,只扫描相关的分区,而不是全表扫描,查询
- 提高数据加载/删除速度:
- 可以快速地加载或删除整个分区的数据,删除旧数据,可以直接
DROP一个分区,这比DELETE成千上万条记录快得多,并且几乎不产生事务日志。
- 可以快速地加载或删除整个分区的数据,删除旧数据,可以直接
- 增强数据维护的便利性:
可以对单个分区进行索引重建、分析、优化、备份和恢复,而不是对整个大表进行操作,大大缩短了维护窗口。
 (图片来源网络,侵删)
(图片来源网络,侵删) - 提高可用性:
如果某个分区的文件损坏,其他分区的数据仍然可以正常访问,可以更快地恢复单个损坏的分区,而不是整个表。
- 均衡 I/O:
可以将不同的分区分布到不同的物理磁盘上,从而分散 I/O 负载,提高并发性能。
分区的类型
MySQL 支持多种分区类型,你可以根据业务场景选择最合适的。
a) RANGE 分区
根据列值的范围进行分区,最经典的应用场景是 按时间范围 分区。
语法:
PARTITION BY RANGE (partition_column) (
PARTITION p202501 VALUES LESS THAN ('2025-02-01'),
PARTITION p202502 VALUES LESS THAN ('2025-03-01'),
PARTITION p202503 VALUES LESS THAN ('2025-04-01'),
PARTITION pmax VALUES LESS THAN MAXVALUE
);
VALUES LESS THAN (value):表示该分区存储所有partition_column值 小于value的行。MAXVALUE:一个无穷大的值,作为最后一个分区的上限,确保所有数据都能被容纳。
示例: 按订单创建时间分区
CREATE TABLE orders (
id INT NOT NULL AUTO_INCREMENT,
order_no VARCHAR(50),
customer_id INT,
amount DECIMAL(10, 2),
create_date DATE NOT NULL,
PRIMARY KEY (id, create_date) -- 注意:分区列必须是主键的一部分
)
PARTITION BY RANGE (YEAR(create_date)) (
PARTITION p2025 VALUES LESS THAN (2025),
PARTITION p2025 VALUES LESS THAN (2025),
PARTITION p2025 VALUES LESS THAN (2025),
PARTITION pmax VALUES LESS THAN MAXVALUE
);
b) LIST 分区
根据列值 预定义的列表 进行分区,当列值是离散的、有限的几个值时,使用 LIST 分区非常合适。
语法:
PARTITION BY LIST (partition_column) (
PARTITION p_region_east VALUES IN (1, 2, 3),
PARTITION p_region_west VALUES IN (4, 5, 6),
PARTITION p_other VALUES IN (DEFAULT) -- DEFAULT 用于匹配未列出的值
);
VALUES IN (value_list):表示该分区存储partition_column值在value_list中的行。DEFAULT:必须提供一个DEFAULT分区来处理所有未明确列出的值。
示例: 按用户所在地区分区
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50),
region_id INT NOT NULL,
PRIMARY KEY (id, region_id)
)
PARTITION BY LIST (region_id) (
PARTITION p_east VALUES IN (1, 2, 3),
PARTITION p_west VALUES IN (4, 5, 6),
PARTITION p_other VALUES IN (DEFAULT)
);
c) HASH 分区
根据用户定义的表达式的返回值进行分区,将数据均匀地分布到多个分区中,当你 没有明显的范围或列表分区键,但又想将数据分散到多个磁盘以 I/O 负载均衡时,HASH 分区是理想选择。
语法:
PARTITION BY HASH(partition_column) PARTITIONS 4; -- 将数据均匀地分散到 4 个分区中
PARTITIONS N:指定分区的数量。- MySQL 会自动计算哈希值,并将数据映射到对应的分区。
示例: 将用户表均匀分散到 4 个分区
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50),
email VARCHAR(100),
PRIMARY KEY (id)
)
PARTITION BY HASH(id)
PARTITIONS 4;
d) KEY 分区
类似于 HASH 分区,但哈希函数是由 MySQL 内部定义的,而不是用户自定义,它使用 PRIMARY KEY 或 UNIQUE KEY 列作为分区键。
语法:
PARTITION BY KEY(id) PARTITIONS 4;
- 优点:当表没有主键但有唯一键时,可以使用唯一键作为分区键,它比 HASH 分区更稳定,因为 MySQL 的内部哈希算法不会改变。
e) 子分区
也称为复合分区,即在一个分区的基础上再进行分区,先按 RANGE(年)分区,再在每个年分区里按 HASH(月)进行子分区。
语法:
CREATE TABLE sales (
id INT NOT NULL AUTO_INCREMENT,
sale_date DATETIME NOT NULL,
amount DECIMAL(10, 2),
PRIMARY KEY (id, sale_date)
)
PARTITION BY RANGE (YEAR(sale_date)) SUBPARTITION BY HASH (MONTH(sale_date)) (
PARTITION p2025 VALUES LESS THAN (2025) (
SUBPARTITION s202501,
SUBPARTITION s202502,
-- ... 12个子分区
SUBPARTITION s202512
),
PARTITION p2025 VALUES LESS THAN (2025) (
SUBPARTITION s202501,
-- ... 12个子分区
SUBPARTITION s202512
)
);
分区的限制与注意事项
分区不是万能的,使用前必须了解其限制:
-
分区键的限制:
- 分区键必须是
PRIMARY KEY或UNIQUE KEY的一部分。 这是 MySQL 5.7 之前非常严格的限制,从 MySQL 8.0 开始,这个限制被放宽了,不再强制要求,但强烈建议将分区键包含在主键中,否则会导致很多问题。 - 分区列必须是
INT类型,或者通过YEAR(),TO_DAYS(),TO_SECONDS(),UNIX_TIMESTAMP()等函数可以转换为INT的类型(如DATE,DATETIME)。
- 分区键必须是
-
函数的限制:
NOW(),RAND(),USER()等不确定的函数不能用在分区表达式中。
-
索引的限制:
所有本地索引(包括主键)都必须包含分区键。
-
外键的限制:
- 分区表不能有外键约束。
-
临时表限制:
TEMPORARY表不能分区。
-
表引擎限制:
- 分区表必须是
InnoDB或NDB引擎,从 MySQL 8.0 开始,MyISAM不再支持分区。
- 分区表必须是
实战演练:创建和管理分区表
假设我们有一个日志表,数据量巨大,我们希望按月进行管理。
步骤 1:创建一个 RANGE 分区表
我们将按 create_time 列的月份进行分区。
CREATE TABLE server_logs (
id BIGINT NOT NULL AUTO_INCREMENT,
log_level VARCHAR(10),
message TEXT,
create_time DATETIME NOT NULL,
PRIMARY KEY (id, create_time) -- 分区列必须包含在主键中
)
PARTITION BY RANGE (YEAR(create_time) * 100 + MONTH(create_time)) (
PARTITION p202501 VALUES LESS THAN (202502),
PARTITION p202502 VALUES LESS THAN (202503),
PARTITION p202503 VALUES LESS THAN (202504),
PARTITION p202504 VALUES LESS THAN (202505),
PARTITION pmax VALUES LESS THAN MAXVALUE
);
YEAR(create_time) * 100 + MONTH(create_time):这是一个技巧,将YYYY-MM格式转换成一个整数(如202501),方便进行范围比较。
步骤 2:插入数据并验证分区
-- 插入一些测试数据
INSERT INTO server_logs (log_level, message, create_time) VALUES
('INFO', 'Server started', '2025-01-15 10:00:00'),
('ERROR', 'Database connection failed', '2025-01-20 11:30:00'),
('INFO', 'User logged in', '2025-02-05 09:15:00'),
('WARN', 'Low disk space', '2025-03-10 14:22:00');
-- 查看数据在哪个分区
SELECT
TABLE_NAME,
PARTITION_NAME,
PARTITION_ORDINAL_POSITION,
TABLE_ROWS,
PARTITION_EXPRESSION
FROM
information_schema.PARTITIONS
WHERE
TABLE_SCHEMA = 'your_database_name' -- 替换成你的数据库名
AND TABLE_NAME = 'server_logs';
你会看到类似下面的结果,数据被正确地分配到了 p202501, p202502, p202503 分区。
步骤 3:验证分区裁剪
这是分区最核心的优势,执行以下查询,并观察 EXPLAIN 的输出。
EXPLAIN SELECT * FROM server_logs WHERE create_time >= '2025-02-01 00:00:00';
关键点:在 EXPLAIN 结果的 PARTITION 列中,你会看到只扫描了 p202502, p202503, pmax 等相关分区,而没有扫描 p202501,这就是分区裁剪,它极大地提升了查询性能。
分区管理常用操作
a) 添加新分区
当数据增长到新的时间范围时,需要添加新分区。
ALTER TABLE server_logs
REORGANIZE PARTITION pmax INTO (
PARTITION p202505 VALUES LESS THAN (202506),
PARTITION pmax VALUES LESS THAN (MAXVALUE)
);
REORGANIZE是一个安全的方式,它不会丢失数据,对于 RANGE 分区,当需要添加一个介于现有分区之间的分区时,必须使用REORGANIZE。- 如果只是想在末尾添加一个分区,可以直接
ADD PARTITION。
b) 删除分区
删除旧数据,比如删除 2025 年 1 月的日志。
ALTER TABLE server_logs DROP PARTITION p202501;
- 这个操作是 瞬时 的,因为它只是删除了一个文件,而不需要逐行删除,效率极高。
c) 合并分区
将多个相邻的分区合并成一个。
ALTER TABLE server_logs REORGANIZE PARTITION p202502, p202503 INTO (
PARTITION p202502_03 VALUES LESS THAN (202504)
);
d) 重建分区
相当于先删除分区数据,再重新插入,可以有效整理分区碎片。
ALTER TABLE server_logs REBUILD PARTITION p202502;
e) 分析/优化分区
ALTER TABLE server_logs ANALYZE PARTITION p202502; ALTER TABLE server_logs OPTIMIZE PARTITION p202502;
总结与最佳实践
-
何时使用分区?
- 大表:当单表数据量达到千万甚至上亿级别时。
- 有明确分区键:查询、删除、加载等操作经常集中在某个特定的数据子集上(如按时间、按地区)。
- 需要简化维护:需要定期归档或删除大量历史数据。
-
何时避免分区?
- 小表:分区本身会带来额外的开销,对于小表可能得不偿失。
- 没有合适的分区键:如果查询条件几乎从不包含分区键,分区将无法带来性能提升,反而会增加管理成本。
- 高并发随机访问:如果应用是典型的 OLTP 场景,大量随机访问单条记录,分区可能不会带来好处。
-
最佳实践:
- 选择合适的分区类型:时间用
RANGE,地区/类别用LIST,负载均衡用HASH/KEY。 - 精心设计分区键:分区键是分区设计的核心,必须与业务查询模式紧密结合。
- 监控分区:定期检查分区的数据分布,防止数据倾斜(某个分区数据量远超其他分区)。
- 自动化管理:对于按时间分区的表,可以编写脚本(如 MySQL Event Scheduler 或外部脚本)来自动添加新分区和删除旧分区。
- 选择合适的分区类型:时间用
希望这份详细的教程能帮助你顺利上手 MySQL 表分区!


