核心概念解释
什么是 GB2312?
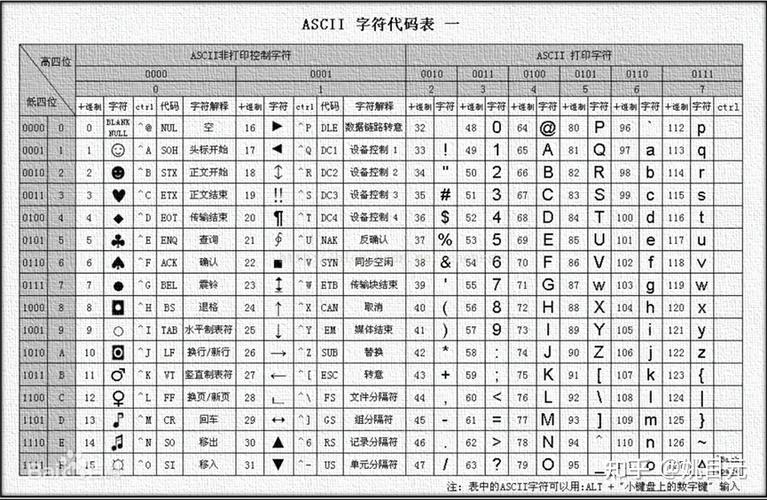
GB2312 是中国国家标准总局发布的《信息交换用汉字编码字符集·基本集》,发布于1980年,它是中文环境下一个非常重要的字符编码标准。

(图片来源网络,侵删)
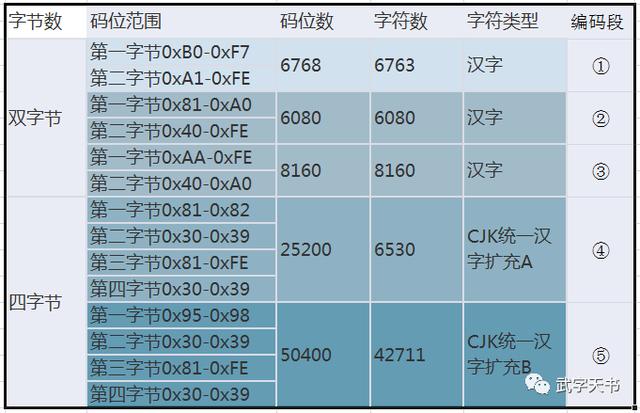
- 特点:它收录了6763个汉字,以及682个非汉字图形字符(如标点、数字、拉丁字母等)。
- 地位:在互联网早期,尤其是在中国大陆的网站上,GB2312 是事实上的标准编码,就像今天 UTF-8 的地位一样。
- 局限性:它的汉字覆盖范围有限,无法处理一些生僻字、繁体字(如“齉”、“𠮷”)或日韩汉字。
为什么现在还会遇到 GB2312?
尽管 GB2312 已经被更先进的编码(如 GBK 和 UTF-8)所取代,但你仍然可能在以下几种情况下遇到它:
- 老旧系统/网站:一些非常老旧的网站、政府机构的内部系统、或者一些企业遗留系统,可能由于维护成本高而一直未更新,仍然使用 GB2312。
- 特定地区:主要是在中国大陆地区。
- 特殊设备:一些工业控制设备、嵌入式系统的显示界面可能仍在使用 GB2312。
作为网页访问者,你可能会遇到什么问题?
当你的浏览器默认编码是 UTF-8(现代浏览器的标准设置)时,如果网页服务器错误地声明了编码为 GB2312,你可能会看到乱码。
乱码的表现:
- 汉字显示为一堆看不懂的符号、方块或问号, 或者 。
- 英文和数字通常不受影响,因为 GB2312 也兼容 ASCII 码。
作为开发者,如何处理 GB2312 的网页?
如果你需要获取、解析或展示一个使用 GB2312 编码的网页,这里有几种解决方案,具体取决于你的角色和工具。
(图片来源网络,侵删)
手动设置浏览器编码(临时解决)
这是最快速、最简单的临时方法,适合普通用户。
- 在浏览器中打开出现乱码的网页。
- 在页面上右键点击。
- 在弹出的菜单中选择“编码”(Encoding)或“字符编码”(Character Encoding)。
- 在子菜单中找到并选择 “简体中文 (GB2312)” 或 “Chinese (Simplified) GB2312”。
选择后,浏览器会重新以正确的编码方式渲染页面,乱码问题通常会立刻解决。
使用编程语言读取和处理(开发者方案)
如果你需要用代码(如 Python, Node.js, Java 等)来抓取和处理这个网页,最关键的一步是在读取数据时指定正确的编码。
Python 示例 (使用 requests 库)
requests 库非常智能,通常会自动处理编码,但如果遇到问题,可以手动指定。
(图片来源网络,侵删)
import requests
url = 'http://example.com/gb2312_page.html'
# 方法1:让 requests 自动检测(通常有效)
try:
response = requests.get(url)
# response.encoding 会根据 HTTP 头信息自动设置
# 如果自动检测失败,可以手动覆盖
response.encoding = 'gb2312' # 关键步骤!
content = response.text
print(content)
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
# 方法2:使用更底层的 urllib,明确指定编码
from urllib.request import urlopen
try:
with urlopen(url) as response:
# 注意:urlopen 返回的是字节流,需要手动解码
byte_data = response.read()
# 使用 decode 方法,并指定编码为 'gb2312'
content = byte_data.decode('gb2312')
print(content)
except Exception as e:
print(f"请求失败: {e}")
关键点:
response.encoding = 'gb2312':告诉requests库,将获取到的字节流用 GB2312 规则转换成字符串。byte_data.decode('gb2312'):这是手动解码字节流的标准做法。
JavaScript (Node.js) 示例 (使用 axios 或 node-fetch)
Node.js 默认使用 UTF-8,所以也需要处理。
const axios = require('axios');
async function fetchGb2312Page() {
const url = 'http://example.com/gb2312_page.html';
try {
// axios 会自动根据响应头的 Content-Type 来设置编码
// 如果服务器没有正确设置,或者设置错误,可能需要手动处理
const response = await axios.get(url, {
// responseType: 'arraybuffer' // 获取原始二进制数据
});
// response.data 已经是乱码字符串,说明自动解码失败了
// 这时你需要先获取二进制数据,再手动解码
const responseBuffer = await axios.get(url, { responseType: 'arraybuffer' });
const content = responseBuffer.data.toString('gb2312'); // 关键步骤!
console.log(content);
} catch (error) {
console.error('请求失败:', error.message);
}
}
fetchGb2312Page();
关键点:
response.data.toString('gb2312'):将Buffer对象(二进制数据)用 GB2312 编码转换成字符串。
从服务器端解决(最佳实践)
如果你是网站的管理者或开发者,最好的办法是将网页的编码升级为 UTF-8。
为什么 UTF-8 是最佳选择?
- 国际通用:它可以表示地球上几乎所有的字符和符号。
- 向前兼容:完全兼容 ASCII,对英文无影响。
- 效率高:变长编码,对英文处理效率高,也能完美支持中文。
- 现代标准:是万维网联盟(W3C)和互联网工程任务组(IETF)推荐的标准。
如何升级?
- 修改 HTML 文件:将 HTML 文件本身的内容从 GB2312 转换成 UTF-8(使用文本编辑器或转换工具)。
- 添加 HTTP 头:在服务器配置中,确保发送
Content-Type头信息为text/html; charset=UTF-8,这是告诉浏览器“我的内容是 HTML,并且用 UTF-8 编码的”。- Apache (
.htaccess):AddDefaultCharset UTF-8 - Nginx (
nginx.conf):charset utf-8; - PHP: 在文件开头加上
header('Content-Type: text/html; charset=UTF-8');
- Apache (
- 添加 Meta 标签:在 HTML 文件的
<head>部分添加<meta charset="UTF-8">,这是作为后备方案,HTTP 头信息丢失或未正确传递,浏览器会读取这个标签。
| 角色 | 问题 | 解决方案 |
|---|---|---|
| 普通用户 | 网页显示乱码 | 浏览器右键 -> 编码 -> 选择 "简体中文 (GB2312)" |
| 开发者/爬虫 | 需要读取 GB2312 网页内容 | 在代码中读取字节流后,使用 .decode('gb2312') 进行解码 |
| 网站管理员 | 网站老旧,使用 GB2312 | 强烈建议升级到 UTF-8,修改文件编码、HTTP 头和 Meta 标签。 |
GB2312 是一个历史悠久的编码,在今天的环境中处理它时,核心就是“识别它”和“指定它”,对于新建项目,请始终优先选择 UTF-8。


